
June 2020: poolp.org, folder pinning and webmail work

Table of Contents
TL;DR:
Reworked my infrastructure at poolp.org, implemented folder pinning, worked on my webmail.
poolp.org infrastructure rework#
I decided to move my servers from online.net to vultr.com (affiliation link).
I have been at online.net for hosting since 2007 and have always been happy with their services, however OpenBSD has never been supported there and I always had to use custom install procedures and hope things go well.
Nowadays, I’m testing a lot of stuff and I create a lot of short-lived machines so going through these procedures each time is painful. I’ve been happy with vultr.com for a little while now so I decided to just move everything there, only keeping a backup server at online.net.
This forced me to rework my setup but also allowed me to improve it as the cost of running multiple VPS is considerably lower than running multiple dedicated servers, I could split multiple services into their dedicated VPS and tidy things a bit. Instead of three servers, I now operate 15 VPS. As time allows, I’ll start documenting on this blog the different parts and their configuration.
It was a bit painful but everything is migrated at this point and the old servers can be shutdown.
The idea behind this infrastructure change is also to start considering the services that I might provide my sponsors in the future :-)
Mail classification heuristics and folder pinning#
A downside of mail commonly shared by users is the problem of mail classification and inbox overload.
Historically mails were dropped in an mbox which is a mail format where all mails are appended to a common mailbox.
This meant that all mails were considered equivalent in priority and were just sorted in delivery time order.
The user had to navigate through them all mixed together and decide which ones they wanted to deal with.
The mbox format was mostly deprecated by the Maildir format which comes with many advantages and uses a directory structure,
rather than a unique mailbox file.
The directory structure allows mail folders to exist as sub-directories making it possible to create dedicated folders,
and use post-processing tools to classify mails in these folders.
For example,
at poolp.org the fdm utility was installed and allowed users to create classification rules which,
in my case,
were used to classify mails from OpenBSD mailing lists into their own folders and out of my Inbox.
This is extra powerful and flexible but not very generic as the rules set by a user may not work for another.
The problem is that even if you can create folders and create rules to put mails in them,
an Inbox essentially replicates the historical behavior of mbox and ends up accumulating all kinds of mails.
If we keep spam and mailing lists aside for now,
the Inbox is still where all commercial mails,
social network notifications,
password recovery,
undelivered mails notifications and other land until you create a rule matching each of them.
Gmail,
despite an interface I dislike,
tackled the issue in a very sound way with their folder tabs:
Primary, Social, Promotions, Updates and Forums.
The Primary folder is the Inbox,
Social is where all social networks notifications land,
Promotions is where bulk mails land,
Updates is where transactional mails land,
and Forums is where mailing lists land.
I wanted to replicate this on my server and it turned out to be very simple as this classification can be done with a few heuristics.
I configured dovecot to expose these additionals folders by default,
then configured fdm to apply a set of rules that would categorize mail in these folders:
action "inbox" maildir "%h/"
action "junk" maildir "%h/.Junk"
action "social" maildir "%h/.Social"
action "bulk" maildir "%h/.Bulk"
action "transactional" maildir "%h/.Transactional"
action "lists" maildir "%h/.Lists"
account "mda" stdin
match "^X-Spam: [Yy]es" in headers action "junk"
match "^X-Facebook-Notify: .*" in headers action "social"
match "^Precedence: list" in headers action "lists"
[...]
match "^Precedence: bulk" in headers action "bulk"
match "^From: .*no-?reply.*" in headers action "transactional"
match all action "inbox"
Every time a mail that I would expect to land in a subfolder hit my Inbox, I looked at its headers and checked what could be used as a discriminator to create a new rule or improve an existing one. This considerably improved the state of my Inbox as most mails that didn’t expect an answer landed in a subfolder, while my Inbox contained mostly mails from people expecting an answer.
This worked wonders for most mails but then there were some that didn’t get proper classification, because sender didn’t do things correctly and made it hard to classify: these mails kept hitting the Inbox and I kept moving them out of the way without being able to write a proper rule. Also, as someone subscribed to multiple mailing-lists, having all mailing-lists mails in a single folder was not comfortable. It occured to me that what was needed on top of these heuristics was folder pinning: if a user receives mail from a sender and moves it to a folder, then most likely future mails from that sender should be moved to that folder too. This would solve the problem of senders that don’t fit generic classification, but also the problem of mails you would like classified in custom folders.
I decided to implement this using three components:
- a mail delivery agent, similar to
fdm, but with extra logic that would take into account the folder pinning; - a key-value store to keep track of folder pinning state;
- a sieve script for learning new pinning states from mail moves in IMAP;
Basically, when a mail arrives at poolp.org the mail delivery agent extracts the sender information, checks in the key-value store if the recipient has a pinning rule for the sender and proceeds to delivery. If there’s a pinning rule then that folder is used, otherwise heuristics are used to find the most likely folder the mail should land in.
If a user is not satisfied with where a mail landed, moving it to a new folder causes dovecot to pass the mail to a sieve script which will extract the sender information, and push a new rule automatically to the key-value store so that next time the mail delivery agent will know where that sender should land.
The sender extraction is done on the Return-Path address, not the From header, which ensures that someone contacting me directly or through a mailing-list is classified in the proper folder, and the fact it is done at the protocol level ensures that this is works regardless of the client used to read mail.
This works very nicely and is particularly pleasant as you quickly forget that it is here, mail just lands where you most expect it. The way I implemented it makes it possible to share in a generic way so that everyone can benefit from this feature, regardless of which MTA they are using, however the code is not ready yet as I wrote it as an experiment for my own setup with hardcoded paths and such. I’ll keep working on it and, when it is ready, I’ll publish my mail delivery agent, the sieve scripts and the dovecot configuration in a single repository.
Webmail work#
As I mentionned in April, I’m currently working on a webmail of my own. Most of the work I did this month was around that project which is evolving at a good pace considering that I had no experience in React, and that it is the end of my scholar year which comes with assignments consuming all of my spare time.
The webmail comes in two parts:
- the backend;
- the frontend;
Backend work#
The backend is just an API that exposes REST endpoints to the underlying IMAP server.
It doesn’t just map a route to an IMAP command but does it in a way that’s optimized for a webmail,
for instance /select is not just selecting a mailbox but also an offset and a limit to lookup envelopes for that mailbox,
avoiding a round-trip for a /fetch.
I wrote a version of the backend in Python and another in Go but eventually decided to stick to Python,
the email parsing library is much more featureful and the performances are just there.
It currently implements:
/login, to authenticate against the IMAP server/noop, which is used by the webmail to keep a connection alive/select, to select afolderand fetch up tolimitenvelopes fromoffset/fetch, to fetch a specific message (currently only headers)/move, to move a set of messages from a folder to another/expunge, to delete a set of messages permanently
This backend can be used as the building block of any mail client so I will publish it as a standalone project, if people are interested in building their webmails they can then focus on the interface and not the lower-level bits.
Frontend work#
The frontend is a React client to that API, plain and simple. I only focused on the folder view at the moment so it is not usable yet to read mails, but it is possible to authenticate, navigate between folders, select and delete or junk mails, etc…
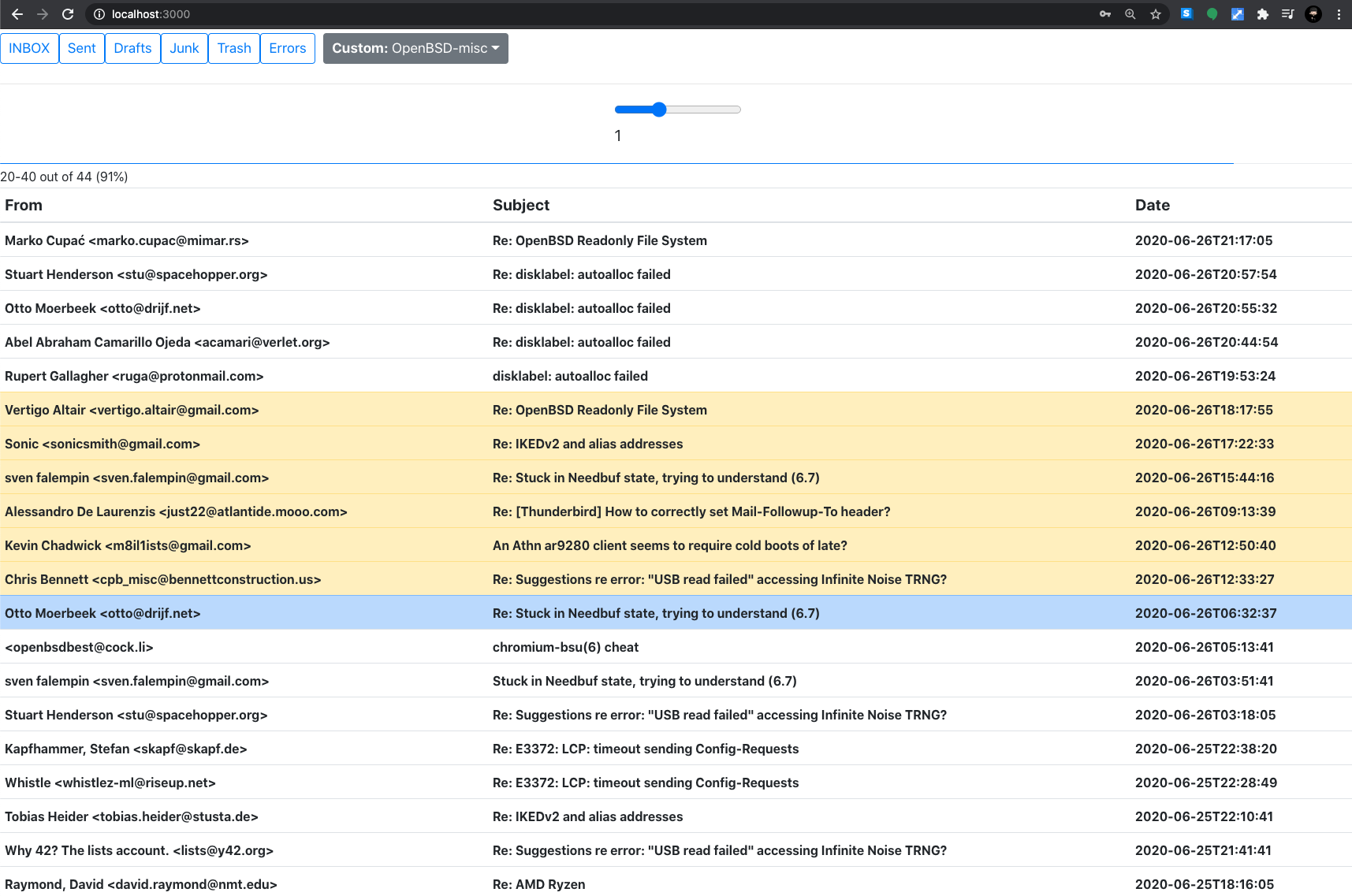
Remember that this is a work in progress at an early stage, not the final interface, but it allowed me to test the behaviors I wanted from the webmail and I’m happy with the result.
You’ll just have to be patient until I put up a live demo so you can test for yourself…
At this point, all I can say is that it is progressing and that some aspects of it are impressive. It is very fast, and this is despite me testing it from my laptop on a remote IMAP server with no caching and no pre-fetching, no optimizations whatsoever.
Patience !
What’s next ?#
My main focus in July will be the webmail, the sooner I get a PoC out the better.
I have some ideas to improve mail classification further in more “creative” ways, I’ll continue exploring how to make mail management nicer.
I have some pending work for OpenSMTPD, both on the filter side and on the queue side.