
Plakar: snapshot forking and tagging

Table of Contents
TL;DR:plakargained two minor features, snapshots fork-ing and snapshots tagging, which makes it possible to unlock several major new features in a relatively short future.
Plakar is not only for backups#
If you have followed my work on this project,
you may have assumed that plakar was intended solely for backups:
it’s not entirely the case.
The most important goal for this project is indeed making backups cheap in resources,
make them versioned,
and as easy as plakar push and plakar pull so there’s no excuses to delay setting backups on any machine…
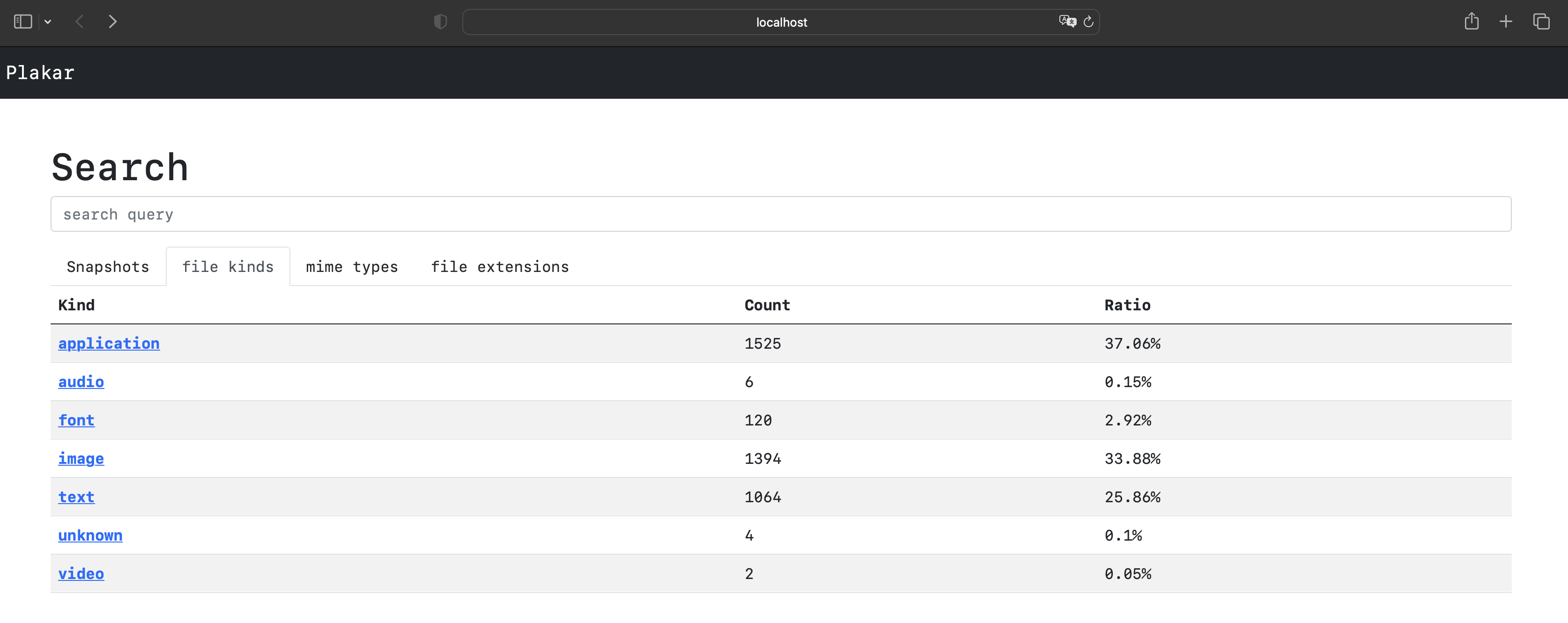
but if you take a look at the web UI you can realise that it goes further than that as plakar also provides classification of files,
a basic search through snapshots,
and I had a proof of concept for a more advanced full-text search in the past and also mentioned image search for a distant future.
My goal for plakar is backups but it is also to make it possible to manage deduped and classified content,
with sharing and synchronizing capabilities: a distributed dropbox on steroids if you will.
That being said…
The problem with plakar#
Early July,
I ran into an issue that made it impossible for me to bring a relatively simple feature to plakar.
Basically,
I wanted to be able to create a snapshot from an s3 bucket and pretend the bucket was a directory and its objects were files.
It turned out that I could not do that…
not because of the design of plakar which can definitely cope with that,
but because of the way I implemented a very specific portion of it that makes it impossible to reach the stage where it actually starts to snapshot.
I decided to leave this for after this summer and work on another feature, which I’ll disclose later, and I ran into the exact same issue: there’s a problem with plakar that makes it hard to do anything that’s not snapshotting an actual directory.
Anatomy of a snapshot#
When you plakar push /some/directory,
what happens is that /some/directory is scanned and its files are split into chunks that are stored somewhere in the repository…
outside of the snapshot.
The snapshot itself basically consists of three things:
- a filesystem view, which represents how files should appear on a filesystem
- an index, which tracks which files consist of which chunks of data
- a metadata view, which allows aggregating informations that are expensive to compute at runtime but that can be saved when snapshot is created
A snapshot by itself is only as big as these three sets of informations. For a 1.4GB snapshot I just did, the data stored in the repository is roughly 900MB after dedup and compression, but the snapshot itself is 730kB on disk and 2.7MB when loaded in memory:
$ plakar push ~/wip/github.com/poolpOrg/poolp.org
$ du -sh ~/.plakar
900M /Users/gilles/.plakar
$ plakar info eac34362|grep Size
[...]
SnapshotSize: 1.4 GB (1379200135 bytes)
MappingIndexDiskSize: 434 kB (433719 bytes)
MappingIndexMemorySize: 1.2 MB (1231917 bytes)
FilesystemIndexDiskSize: 296 kB (296028 bytes)
FilesystemIndexMemorySize: 1.5 MB (1455300 bytes)
This is what makes it cheap as new snapshots will point to the same data stored in repository, and will only consume the size of the index and filesystem views which are considerably smaller. I’m not mentionning the metadata because it’s even smaller (less than 4kB).
The issue with filesystem view#
What is problematic is that the I built the filesystem view assuming that it would be populated from an actual filesystem:
it’s entry point is a Scan() method that takes an actual directory,
then you end up with an object matching that directory and its content.
This works only when dealing with a real filesystem,
which is not the case with s3 or postgresql or anything else I’d like to be able to snapshot…
The filesystem view should not be mirroring a directory, what it should do is expose an API that allows me to mirror a directory but that also allows me to build it node by node, so that I can craft a fake filesystem view from something that’s not an actual filesystem.
This is going to require some work but the good part is that this would not change the format of the resulting view,
so I could still keep the Scan() method for dealing with a real filesystem,
and could add methods that are missing to allow crafting a filesystem view from something else.
Existing snapshots would not be broken,
code that relies on scan would remain unchanged,
it’s far from the pain I first envisionned when I understood the issue.
Splitting in different packages#
I did a bit of refactoring to extract the filesystem view, the indexing code and the metadata out of the snapshot package, if only to ensure that snapshots were not abusing private members or methods, and after a bit of cleaning everything is fine.
This was a preliminary step to start working on improving the filesystem view, something that I will start doing in August.
Snapshot fork-ing#
The first feature I introduced yesterday is a relatively pointless feature for users, but a very interesting feature from an implementation point of view.
The snapshot layer in plakar used to only support creating a snapshot or loading a snapshot, the former being “finalized” by a commit, the latter being a read-only representation of a committed snapshot (committing would cause a panic).
The workflow was simple and hidden behind the CLI commands,
where plakar push would create a snapshot, build its filesystem view and index, then commit it,
and where any other command would essentially load an existing snapshot and look into its filesystem view or index to do something useful.
I introduce the ability to fork a snapshot,
which creates an exact copy of the snapshot with the same filesystem view and index,
pointing to the same repository data chunks,
but…
uncommited so that the filesystem view and index can be altered before the forked snapshot is committed.
From a CLI point of view,
there’s nothing useful to do with this,
if you run plakar fork on a snapshot,
you get a new exact copy with a different snapshot ID:
$ plakar ls
2023-07-23T08:33:19Z eac34362 1.4 GB 8s /Users/gilles/wip/github.com/poolpOrg/poolp.org
$ plakar fork eac34362
$ plakar ls
2023-07-23T08:33:19Z eac34362 1.4 GB 8s /Users/gilles/wip/github.com/poolpOrg/poolp.org
2023-07-23T08:33:19Z b3027af1 1.4 GB 8s /Users/gilles/wip/github.com/poolpOrg/poolp.org
$
But from a developer point of view, this means that “layering” could be implemented easily: fork a snapshot, apply a small change and commit, you get an entirely new snapshot that’s exactly the previous one with the change, at the cost of a snapshot but faster than if you had scanned the directory again.
Basically,
this allows implementing a virtual file system in plakar,
where you can actually instruct it to create directories or files,
without resorting to scanning an actual filesystem.
Snapshot tagging#
The other interesting feature is that of snapshot tagging, which allows assigning one or many tags to a snapshot as it is being created, then using these tags in place of snapshot identifiers to reference the last one carrying the tag.
$ plakar push -tag website ~/wip/github.com/poolpOrg/poolp.org
$ plakar ls website:/Users/gilles/wip/github.com/poolpOrg/poolp.org
2023-07-19T08:40:19Z drwxr-xr-x gilles staff 512 B .git
2023-07-17T11:17:57Z drwxr-xr-x gilles staff 128 B .github
2023-07-18T13:10:56Z -rw-r--r-- gilles staff 120 B .gitmodules
2023-07-17T15:57:35Z -rw-r--r-- gilles staff 0 B .hugo_build.lock
2023-07-17T11:17:57Z -rw-r--r-- gilles staff 196 B README.md
2023-07-18T09:23:03Z drwxr-xr-x gilles staff 160 B assets
2023-07-17T11:17:57Z drwxr-xr-x gilles staff 96 B config
2023-07-18T21:31:17Z drwxr-xr-x gilles staff 160 B content
2023-07-17T11:17:58Z drwxr-xr-x gilles staff 96 B data
2023-07-17T17:19:23Z drwxr-xr-x gilles staff 160 B layouts
2023-07-17T11:17:58Z -rw-r--r-- gilles staff 68 kB package-lock.json
2023-07-17T11:17:58Z -rw-r--r-- gilles staff 897 B package.json
2023-07-18T21:48:31Z drwxr-xr-x gilles staff 928 B public
2023-07-17T15:57:35Z drwxr-xr-x gilles staff 96 B resources
2023-07-18T09:23:03Z drwxr-xr-x gilles staff 192 B static
2023-07-17T11:17:58Z -rw-r--r-- gilles staff 467 B tailwind.config.js
2023-07-18T13:10:56Z drwxr-xr-x gilles staff 96 B themes
$ plakar cat website:/Users/gilles/wip/github.com/poolpOrg/poolp.org/tailwind.config.js
module.exports = {
content: [
"./content/**/*.md",
"./content/**/*.html",
"./layouts/**/*.html",
"./assets/**/*.js",
"./themes/digitalgarden/content/**/*.md",
"./themes/digitalgarden/content/**/*.html",
"./themes/digitalgarden/layouts/**/*.html",
"./themes/digitalgarden/assets/**/*.js",
],
darkMode: 'class',
theme: {
extend: {},
},
plugins: [require('@tailwindcss/typography'), require('@tailwindcss/line-clamp')],
}
The CLI currently only allows setting one tag, but in practice this was implemented by adding an array of tags to snapshot metadatas, so technically a snapshot can carry multiple tags.
Furthermore, something that’s a voluntary limitation, is that tags are carried by the snapshots themselves and not by the repository. This means that once a snapshot is created, its tags are not alterable… except if it is forked, retagged and committed under a new snapshot ID.
This is important because plakar currently supports synchronizing snapshots from a different repository, and having synchronization of snapshots carry their own tags is necessary for a feature I’m working on.
Where is this all heading to ?#
So, the fork feature is heading nowhere visible to users, the benefits will be in the addition of visible features that would rely on it.
The tagging feature however makes it possible to assign a memorable name to a set of related snapshots,
and point to the latest version of it,
as you could see from my examples tagging the push of ~/wip/github.com/poolpOrg/poolp.org as website.
Plakar supports restore-less browsing of snapshots, including through a web UI, so if I somehow added the ability to “publish” tags as read-only public endpoints, it could be used not only for backups but also for publically sharing data that’s searchable, classified and de-duped.
In other words,
I could tag pictures my ~/Pictures folder and expose it to the world if I wanted to,
and my instance of plakar would always reflect the latest plakar push -tag pictures ~/Pictures.
Not only that,
but because plakar supports proxying other plakar instances,
people could have their own plakar proxy my tag to their own users…
or better yet,
because plakar supports synchronizing snapshots,
people could mirror my tag in their own instance in case mine disappeared:
the snapshot carries a repository ID,
so the snapshot could always be tied to its original repository.
This could come with issues, who knows if someone has not tweaked the snapshot, or if they didn’t publish a snapshot with other content and tagged it as mine to pretend I published some data… this is where signatures come into play.
There’s already placeholders for signatures in the code, I had written the code but removed it because I thought it was too early and needed more thinking. Now is the time to work on reintroducing them, as well as a mean for people to maintain a keyring of identities.
It should be possible for someone to track the projects tag of my public plakar,
synchronize it on their own instance if they want a mirror,
and for others to read it from that mirror and still be sure that it’s really data that I exposed.
What’s next ?#
Work on signatures and keyrings obviously.
I had previous work done on signatures, assuming user-signed snapshots to allow teams to assign responsibilities to specific users, but repository-specific signatures may be a trail to follow and investigate.
More on this in a future article.
Anything to add GPT-4 ?#
Anything else to add dear co-author ?
From the looks of it, plakar is evolving into a more comprehensive tool, morphing from a simple backup solution into something far more versatile. Sharing, distributing, and managing content with newfound capabilities, a testimony to the potential of great software design.
What’s significant to acknowledge about plakar is its potential to go beyond its primary role as a backup tool. It has the capabilities to manage deduplicated and classified content, along with efficient sharing and synchronization.
Remember, dear readers, these are just my two cents added to the rich dialogue initiated by the original author. The world of software design is vast and wonderfully complex, and there’s always more to explore and discuss!
That was … well … keep working on your style buddy.